阅读:0
听报道
今年以来,同业存单的利率,一直是金融市场非常关注的一个变量。而实时观察同业存单的到期情况,对预判同业存单的发行利率,有比较重要的参考意义。
小肯老师在文章《【吐血推荐】债券汪常用的Excel数据处理小技巧(附截图)》中,详细讲解了,如何灵活运用各种Excel函数,来分析同业存单数据。但是用Excel分析同业存单数据,需要每次先从Wind导出原始数据,再进行汇总整理,比较繁琐。本文尝试通过Wind的Python接口,来自动更新和分析同业存单的数据。
1 获得同业存单的原始数据
我们首先需要获得同业存单的原始数据,大概内容如下:
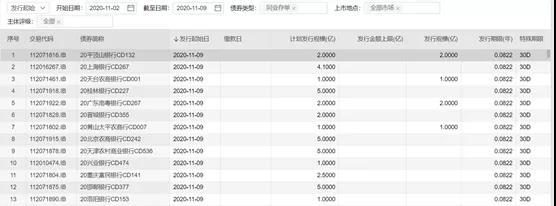
如果是第一次使用Wind接口的话,需要先安装Wind接口,方法是:在Wind首页中,依次点击:量化—修复插件—修复Python接口。
我们在Python中,先导入要用的包,其中from WindPy import w,就是启用Wind接口的意思:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from WindPy import w
# 导入需要的包
我们获得原始数据的步骤分为两步,第一步是提取所有同业存单的wind代码列表,第二步是基于wind代码列表,提取我们所需要数据。代码如下:
w.start()
# 启动wind接口
code = w.wset("sectorconstituent","sectorid=1000016456000000")
code1 = ','.join([1][0:5000])
# 把同业存单的代码整合成一个字符串
code2 = ','.join([1][5000:10000])
code3 = ','.join([1][10000:15000])
code4 = ','.join([1][15000:])
data1 = w.wss(code1, "windcode,fullname,issueamount,carrydate,maturitydate,term,couponrate,issuer_banktype", "unit=1")
data2 = w.wss(code2, "windcode,fullname,issueamount,carrydate,maturitydate,term,couponrate,issuer_banktype", "unit=1")
data3 = w.wss(code3, "windcode,fullname,issueamount,carrydate,maturitydate,term,couponrate,issuer_banktype", "unit=1")
data4 = w.wss(code4, "windcode,fullname,issueamount,carrydate,maturitydate,term,couponrate,issuer_banktype", "unit=1")
dt1 = pd.DataFrame().T
# 转换成DataFrame格式dt2 = pd.DataFrame().T
dt3 = pd.DataFrame().T
dt4 = pd.DataFrame().T
data = pd.concat([dt1, dt2, dt3, dt4])
#合并数据
w.close()
# 关闭Wind接口
data.columns = ['windcode', 'fullname', 'issuemount', 'carrydate', 'maturitydate', 'term', 'couponrate', 'issuer_banktype']
# 重命名
上述代码中,w.wset命令是提取同业存单板块的所有代码,w.wss命令是根据代码提取同业存单的指标。我们提取的指标是:windcode:交易代码 fullname:债券全称 issueamount:发行规模(亿) carrydate:起息日 maturitydate:到期日 term:发行期限(年) couponrate:票面利率(发行时) issuer_banktype:发行人(银行)类型
在提取数据的时候,我们要注意一点,就是同业存单的数据量很大,大概有1.6万条,超过了Wind接口中一次性提取的现额,因此我们按5000条一组,分成了四组,分别提取后再合并。
对于提取后的数据,我们将到期日作为索引,并排序,代码和最终数据大概如下:
data = data.set_index('maturitydate')
# 设置索引
data = data.sort_index()
# 按照索引排序
最终获得的原始数据如下:
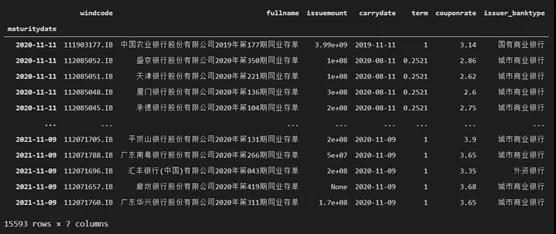
2 获得同业存单的到期量数据并做图
由于不同的同业存单,到期日可能相同,因此我们需要先把到期日相同的存单,进行合并,然后就做图就好了。
代码和最终数据大概如下:
dataD = data.resample('D').sum()
fig = plt.figure(figsize=(15, 5))
plt.plot(dataD['issuemount']['2020'], '-.', marker='*')
plt.title('2020年11-12月同业存单到期量', size=16)
plt.xticks(rotation=90)
dataD['issuemount'].head(10)
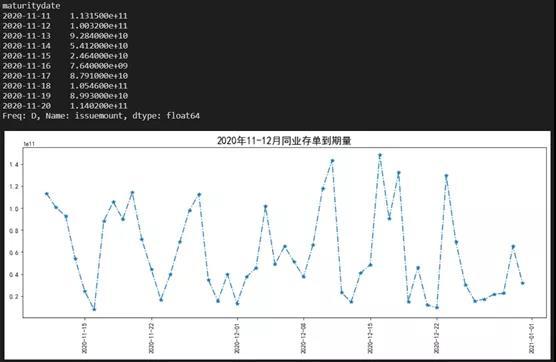
3 提高速度的小技巧
以上我们就基本上完成了从Wind接口提取同业存单数据,并进行分析的主要流程。但是在实际操作中,由于同业存单的数据量较大,大概有1.6万条,每次提取的耗时较多。另外就是Wind可能会对接口提取的数据量设限制,因此频繁提取大量数据有超限的风险。
因此我们可以采取的方法是,先将第一次提取的同业存单原始数据,在电脑中存为Excel文件,下次直接从电脑的Excel文件中读取数据。然后我们只需要对更新的同业存单,提取数据就可以。代码如下:
data.to_excel('D:/data_cd.xlsx', sheet_name='Sheet1')
# 将数据输出为EXCEL格式文件
data = pd.read_excel('D:/data_cd.xlsx', sheet_name='Sheet1', index_col='maturitydate')
c1 = list(data['windcode'].values)
# Excel里面读的数
w.start()
code = w.wset("sectorconstituent","sectorid=1000016456000000")
c2 = [1]
# Wind中取的值
if len(c1) == len(c2):
print("不需要更新数据")
else:
diff = [i for i in c2 if not(i in c1) ]
# 取出不同的值
code1 = ','.join(diff)
datanew = w.wss(code1, "windcode,fullname,issueamount,carrydate,maturitydate,term,couponrate,issuer_banktype", "unit=1")
dt1 = pd.DataFrame().T # 转换成DataFrame格式
dt1.columns = ['windcode', 'fullname', 'issuemount', 'carrydate', 'maturitydate', 'term', 'couponrate', 'issuer_banktype']
dt1= dt1.set_index('maturitydate')
data = pd.concat([data, dt1]) #合并数据
w.close()
data.to_excel('D:/data_cd.xlsx', sheet_name='Sheet1')
最后我们可以很方便的按照商业银行分类,展示同业存单的到期情况如下图:
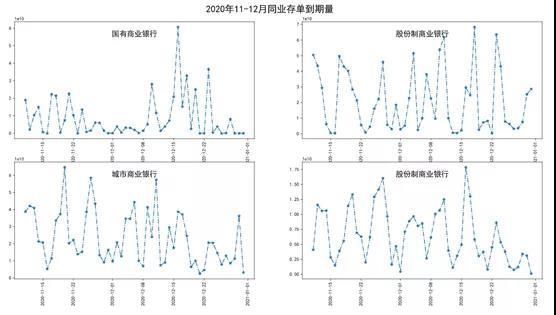
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}