阅读:0
听报道
无论做什么研究工作,都需要及时获取最新的外部信息。一个传统的方法是,收藏自己感兴趣的网址,然后每天挨个打开一遍,这种方法耗时耗力。
最近看到公众号《数字生命卡兹克》的一篇分享20个群都来问我的AI早报,是这么做的。给了我们启发,笔者尝试了借助AI制作宏观信息日报的方法,分享如下:
总的来说,可以分为三步:
第一步,寻找自己感兴趣的网站,并转换成XML格式;
第二步,借助AI写代码提取信息;
第三步,借助大模型的API接口处理自己感兴趣的信息,并保存。
第一步,举个例子,我们对圣路易斯联储的工作论文比较感兴趣,希望保持跟踪,网页内容如下:

然后我们将其转换成XML文件如下:
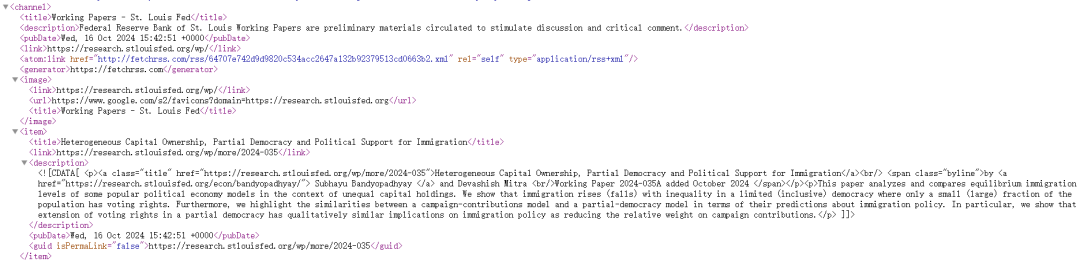
之所以转换成XML文件,主要是便于后续提取信息。从XML文件看,item 包含了感兴趣的文章信息,其中,title 是标题,link 是链接,description 是摘要,pubDate 是发布日期。
第二步,我们借助AI写代码提取相关信息
import feedparserfrom datetime import datetime, timedeltaimport tkinter as tkfrom tkinter import simpledialogimport redef extract_second_paragraph(description):match = (r'<p>(.*?)</p>.*?<p>(.*?)</p>', description, re.DOTALL)if match:return (2).strip()return descriptiondef fetch_rss_feed(url, days_to_show):try:feed = feedparser.parse(url)if feed.bozo:raise Exception(f"Error parsing feed: {feed.bozo_exception}")current_date = ()()print(f"Title: {feed.feed.title}")print(f"Link: {}")print(f"Description: {feed.feed.description}")print("\n")for entry in feed.entries:if 'published' in entry:published_date = datetime.strptime(entry.published, "%a, %d %b %Y %H:%M:%S %z")()if current_date - timedelta(days=days_to_show) <= published_date <= current_date:print(f"Title: {entry.title}")print(f"Link: {}")formatted_date = published_date.strftime("%Y-%m-%d")print(f"Published: {formatted_date}")summary = extract_second_paragraph(entry.summary)print(f"Summary: {summary}")print("\n")except Exception as e:print(f"An error occurred: {e}")def main():xml_url = "your.xml"root = ()root.withdraw()days_to_show = simpledialog.askinteger("Input", "Enter the number of days to show:", parent=root, minvalue=1)if days_to_show is not None:fetch_rss_feed(rss_url, days_to_show)else:print("No number entered. Exiting.")if __name__ == "__main__":main()
在上述代码中,我们除了提取相关信息之外,还做了一个额外的操作,就是把发布日期转换成了DateTime格式,并提供了一个窗口,供用户输入一个数字X,来提取当前日期X天之前至今的文章。如果每天都运行一遍的话,也可以设置默认值为1天。
运行后,我们可以看到提取结果:

第三步,我们希望对提取结果做一些处理,比如说把摘要翻译成英文,并导出外部文件。
我们使用的是智谱AI大模型,智谱AI给出了一个参考示例:
from zhipuai import ZhipuAI# 初始化ZhipuAI客户端,请替换""为您的实际API Keyclient = ZhipuAI(api_key="your_api")# 调用翻译模型,这里以"embedding-2"模型为例,输入需要翻译的文本response = client.embeddings.create(model="embedding-2", #填写需要调用的模型编码input="你好",)# 打印翻译结果print(response)
我们把智谱AI嵌入,并可以获得我们想要的结果了。如果有多个感兴趣的网站,可以逐一提取并合并,就可以获取我们感兴趣的宏观信息日报了。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}